Some important topics in Statistics:
- Central Limit Theorem
- Mean
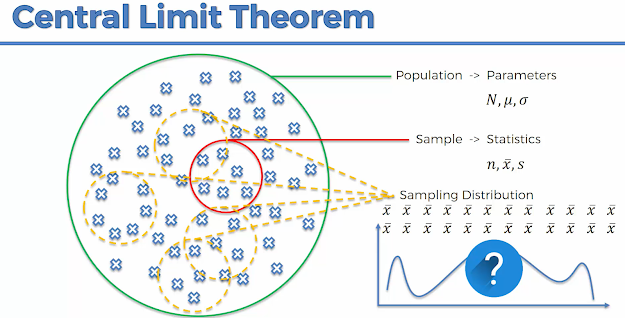
CLT Statement:
For large sample sizes, the sampling distribution of means will approximate to normal distribution even if the population distribution is not normal.
If we have a population with mean μ and standard deviation σ and take large random samples (n ≥ 30) from the population with replacement, then the distribution of the sample means will be approximately normally distributed.
Why CLT is important?
The field of statistics is based on fact that it is highly impossible to collect the data of entire population. Instead of doing that we can gather a subset of data from a population and use the statistics of that sample to draw conclusions about the population.
In practice, the unexpected appearance of normal distribution from a population distribution is skewed (even heavily skewed). Many practices in statistics such as hypothesis testing make this assumption that the population on which they work is normally distributed.
This assumption basically simplifies matters and we overcome the problem of the data belonging to the population which is not normal.
Thus, even we don’t know the shape our distribution where our data comes from but according to Central Limit Theorem we can treat sampling distribution of any population as normal. Of course, for the conclusions of the Central Limit Theorem to hold we need sample size to be large enough.
Mean
It is the average of all the values, if I ask you “approximately how much time do you take to travel to a destination from your home?”, then you may answer 1 hour if you live significantly away from that destination, but why would you answer “1 hour”? , you might have answered :
- 1 hr 55 min
- 1 hr 56 min
- 2 hr 01 min
- 2 hr 20 min etc…
But still, you choose to say “well, generally it takes me 1 hour to reach there…”
That’s what mean is, mean is the average of all the values you have divided by the number of values you have.
Median
Median is nothing but the middle value of the data you have
Mode
Mode is nothing but the most frequent object/value present in your dataset, for example, you went to the market and bought some fruits something like this:
- 3 oranges
- 2 apples
- 6 bananas
- 4 strawberries
- 1 pineapple
So the most frequent fruit of them all would be, bananas, That’s what ‘mode’ is, in this dataset banana is their mode, note that we used categorical data in the example and not numerical data.
Comments
Post a Comment